
Las estrategias de crecimiento inorgánico, como las fusiones y adquisiciones (M&A), actúan como palancas estratégicas de crecimiento, permitiendo a las empresas realizar sinergias de ingresos y costes o adquirir rápidamente capacidades emergentes que proporcionen una ventaja competitiva a largo plazo. Hoy en día, por ejemplo, observamos cómo grandes organizaciones adquieren start-ups de IA más pequeñas e innovadoras para acelerar sus esfuerzos de transformación de la IA y obtener una ventaja competitiva.
La integración tecnológica desempeña un papel crucial en la captura de valor de M&A. Un estudio de Deloitte sostiene que la TI es un factor clave de las ventajas de la integración, ya que representa más del 50 % de todas las sinergias. Sin embargo, debido a la proliferación de silos de datos y a las diversas arquitecturas y entornos tecnológicos, las organizaciones se enfrentan a varios desafíos de datos posteriores a la fusión para obtener los beneficios de la integración tecnológica.
Este artículo presenta un marco de cinco pasos para abordar esos desafíos y acelerar la captura de valor en los entornos de M&A. Este marco garantizará que tu estrategia de datos tras la fusión con Cloudera ofrezca las capacidades necesarias para agilizar el proceso de integración tecnológica.
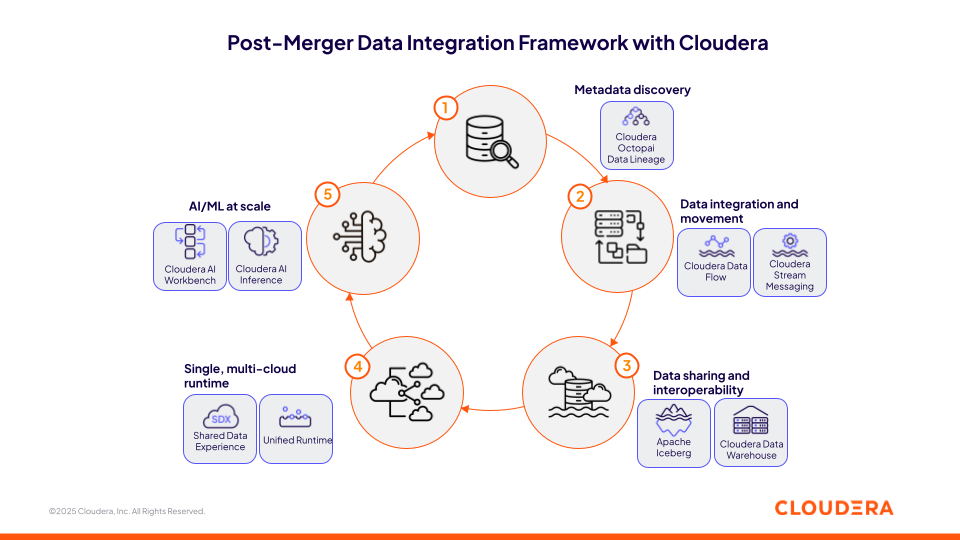
Figura 1: Marco de integración de datos posterior a la fusión con Cloudera
1. Acelere la integración posterior a la fusión con Cloudera Octopai Data Lineage
Al inicio de la integración posterior a la fusión, la fase de detección de datos suele convertirse en un cuello de botella, ya que las fuentes fragmentadas y no documentadas retrasan los esfuerzos críticos de análisis y cumplimiento. Cloudera Octopai Data Lineage aborda este desafío proporcionando una solución automatizada de gestión de metadatos impulsada por IA que acelera la detección de datos, el linaje de extremo a extremo y el catalogado en entornos híbridos y multinube complejos.
Cloudera Octopai Data Lineage mapea eficazmente los flujos de datos y llena los vacíos de metadatos, proporcionando un linaje multidimensional que rastrea los orígenes y las transformaciones para una visibilidad total. Con más de 60 integraciones nativas y conectores universales para sistemas no nativos, Cloudera Octopai Data Lineage agiliza la incorporación de conjuntos de datos adquiridos, mejorando así la transparencia, calidad y confianza de los datos.
Por ejemplo, en escenarios de fusiones bancarias, esta capacidad facilita la rápida identificación y etiquetado de conjuntos de datos relacionados con el riesgo, garantizando el cumplimiento de normas reguladoras como la BCBS 239, al mismo tiempo que minimiza la necesidad de extensas auditorías o intervenciones manuales.
2. Integrar fuentes de datos dispares con los datos en movimiento de Cloudera
Integrar fuentes de datos diversas y eliminar pipelines ETL complejos y personalizados es un desafío crítico tras la fusión. Cloudera ofrece capacidades robustas para la ingesta de datos, procesamiento y distribución de datos por lotes y en tiempo real a través de Cloudera Data Flow (impulsado por Apache NiFi) y Cloudera Streaming (impulsado por Apache Kafka y Apache Flink).
Con más de 450 conectores, Cloudera Data Flow ofrece una interfaz visual de arrastrar y soltar para consumir datos de una variedad de fuentes heterogéneas, ya sea en las instalaciones, en las nubes o en el borde. Además, Cloudera Streaming proporciona una arquitectura de bus de mensajería que desacopla los sistemas de origen de los sistemas consumidores entre las dos entidades, eliminando así las integraciones punto a punto que añaden complejidad arquitectónica y mayores costes.
Durante la integración posterior a la fusión, estas capacidades pueden acelerar y simplificar significativamente el movimiento de datos entre organizaciones. Por ejemplo, Cloudera Data Flow puede utilizarse para integrar rápidamente datos locales de sistemas fuente heredados de la empresa adquirida en el almacen de datos nativo en la nube de la empresa matriz, acelerando la toma de decisiones.
3. Crear una capa de intercambio de datos segura en Cloudera Open Data Lakehouse con Apache Iceberg.
El intercambio de datos entre las entidades que se fusionan es un requisito esencial para la toma de decisiones integradas y la obtención de conocimientos. Este proceso puede ser complejo debido a las diversas tecnologías de análisis exploratorio y de business intelligence, así como a los distintos modelos de seguridad de los datos utilizados por los diferentes sistemas.
Un enfoque de lakehouse de datos abierto que combine Apache Iceberg, el catálogo REST de Iceberg de Cloudera y Cloudera Shared Data Experience (SDX) permite a las organizaciones desarrollar una capa unificada de intercambio de datos. Esta capa es compatible con varios motores analíticos (por ejemplo, Snowflake, Databricks, AWS EMR, AWS Athena y Salesforce Data Cloud, siempre que estos motores estén habilitados para el catálogo REST de Iceberg) y proporciona un modelo de seguridad y gobierno detallado para gestionar el acceso de una amplia gama de usuarios, incluidos los equipos de ciencia de datos recientemente integrados.
Por ejemplo, dos organizaciones sanitarias que se dedican a la fabricación de medicamentos pueden aprovechar Cloudera para crear un lakehouse de datos compatible con GxP que consolide los activos de datos de las entidades que se fusionan y, al mismo tiempo, garantice el cumplimiento de los requisitos reglamentarios.
4. Estandarizar iniciativas interambientales en un único entorno multinube
Los diferentes entornos utilizados para actividades analíticas en las dos entidades que se fusionan conducen a operaciones duplicadas a lo largo del ciclo de vida de los datos, incluyendo múltiples pipelines de ingeniería de datos para tareas comunes como la ingesta de datos y estandarización de datos.
Cloudera permite a las organizaciones estandarizar datos y operaciones de IA en un tiempo de ejecución común en diversos entornos de nube privada y pública. Esta capacidad se deriva del modelo de infraestructura en contenedores subyacente utilizado en todos los entornos, un mecanismo de autenticación y autorización de usuarios consistente (Cloudera SDX) y Cloudera Manager, que sirve como panel único para administrar clústeres en diferentes entornos de implementación y regiones.
En un contexto posterior a la fusión, esta estandarización es transformadora: las dos empresas pueden integrar sus operaciones del ciclo de vida de los datos en un único entorno de ejecución, eliminando herramientas redundantes y facilitando el intercambio de datos, conocimientos y modelos de IA. Esto conduce a una reducción de los costes tecnológicos y laborales para las operaciones de datos y el desarrollo de modelos de IA/ML, un aumento de la productividad de los profesionales, la consolidación de múltiples herramientas y la reducción de silos de datos.
5. Escalar las iniciativas de IA en cualquier lugar con la IA de Cloudera
Tras la adquisición o fusión, el reto inmediato es integrar las diversas herramientas, modelos y científicos de datos de la startup innovadora recién adquirida, todo ello gestionando la demanda cambiante de capacidad. Cloudera AI Workbench e AI Inference permiten a las organizaciones escalar iniciativas de IA tanto en las instalaciones como en la nube al:
Proporcionar una solución integral basada en contenedores para la ingeniería de características, el entrenamiento de modelos, el seguimiento de la experimentación y el despliegue de modelos.
Facilitar el intercambio de modelos de IA que permiten a los científicos de datos colaborar entre equipos dispares
Aprovechar servicios de aceleración de hardware y software de socios de Clouder que pueden acelerar todo el ciclo de vida de la ciencia de datos mejorando el rendimiento de ingeniería de datos en 20 veces y el rendimiento de inferencia de IA hasta seis veces.
Con Cloudera, la empresa integrada puede lograr una reducción sustancial de costes al trasladar las cargas de trabajo persistentes e intensivas en cómputos, como el modelo de IA y aprendizaje automático, a entornos locales. Y lo que es más importante, puede acelerar el tiempo de comercialización de nuevas aplicaciones combinadas de IA. Esto permite que la organización obtenga rápidamente la “ventaja competitiva” que buscaba en primer lugar con la fusión y adquisición.
Da el siguiente paso para asegurar una integración exitosa tras tu próxima fusión y adquisición
Cloudera puede acelerar la integración de los activos de datos y las capacidades analíticas entre las dos entidades integradoras tras la fusión. Nuestra plataforma ofrece escalabilidad a lo largo del ciclo de vida de los datos, un modelo de implementación independiente de la infraestructura e interoperabilidad del lakehouse de datos en los servicios de Cloudera y Apache Iceberg. Esta combinación proporciona un modelo arquitectónico para estandarizar las iniciativas de IA/ML y las operaciones de datos, y para ofrecer un modelo de intercambio de datos que puedan utilizar tanto los servicios de Cloudera como los que no son de Cloudera.
Para programar una demostración o una visita al producto, ponte en contacto con nuestro equipo.
