Democratiza los datos para la IA utilizando la interoperabilidad entre motores y la colaboración de datos sin duplicación




Cómo el catálogo REST de Iceberg de Cloudera permite a las empresas ser abiertas y estar preparadas para la IA.
La interoperabilidad ha sido durante mucho tiempo una palabra de moda, no una capacidad con la que las empresas puedan contar en la práctica. En cambio, los arquitectos de datos a menudo se ven obligados a unir sistemas fragmentados, los directores de datos se enfrentan a riesgos enormes y a la dependencia de un único proveedor debido a un gobierno aislado, y los responsables de las plataformas no pueden ofrecer una visión coherente de los datos a sus equipos. Ya sea impulsado por fusiones, estrategias multinube o asociaciones externas, el patrón se repite: aumento de los costes, innovación más lenta y capacidad limitada para escalar la IA con confianza.
En Cloudera, hemos ayudado a nuestros clientes a superar estos retos: capas de metadatos desconectadas, pipelines de datos duplicados y modelos de gobierno que no se extienden a las herramientas, siempre esforzándonos por habilitar empresas abiertas y preparadas para la IA que desbloqueen la interoperabilidad a gran escala.
Por qué la apertura es importante para la IA empresarial
Para ampliar las cargas de trabajo de la IA, las organizaciones necesitan visibilidad y control sobre los datos que las alimentan. La inteligencia de metadatos desempeña un papel fundamental en esta ecuación, ya que permite a las organizaciones comprender dónde residen los datos, cómo están estructurados y cómo se utilizan en los distintos equipos y herramientas.
Con estándares abiertos como Apache Iceberg y el catálogo REST de Iceberg, las empresas obtienen una capa unificada de metadatos que soporta el intercambio de datos sin ETL, hace cumplir el gobierno y permite asegurar la interoperabilidad entre motores de análisis e IA. Esta base transforma la infraestructura fragmentada en una arquitectura de datos conectada y preparada para la IA, en la que los metadatos se convierten en la clave para acelerar el acceso a la información y, al mismo tiempo, mantener la confianza.
Abierto, seguro y sencillo: catálogo REST de Iceberg de Cloudera
El catálogo REST de Iceberg de Cloudera impulsa nuestro lakehouse de datos abierto y ayuda a las organizaciones a simplificar la arquitectura, reducir duplicaciones y extender el acceso seguro a los datos donde sea necesario.
Actúa como una capa de metadatos universal e interoperable y proporciona acceso sin copia a las tablas de Iceberg en todas las herramientas, nubes y equipos, lo que permite a las herramientas de código abierto y de terceros acceder a los mismos datos. Entre las características y los beneficios se incluyen:
- Abierto e independiente del motor: proporciona API basadas en estándares que admiten herramientas como Athena, Databricks, Redshift y Snowflake, lo que permite la interoperabilidad sin depender de un proveedor
- Desacoplado por diseño: abstrae los motores de consulta de los metastores backend, reduciendo la complejidad y aumentando la portabilidad entre entornos.
- Acceso a los metadatos en tiempo real: admite consultas de metadatos rápidas y actualizadas desde metastores compatibles con Iceberg, lo que mejora la visibilidad de los datos en todos los equipos
- Gobernado y seguro: amplía los controles de acceso detallados, los permisos a nivel de fila y la integración de la gestión de identidades y accesos (IAM) empresarial (como LDAP y OAuth2) a todos los sistemas conectados, lo que garantiza la aplicación coherente de las políticas a gran escala
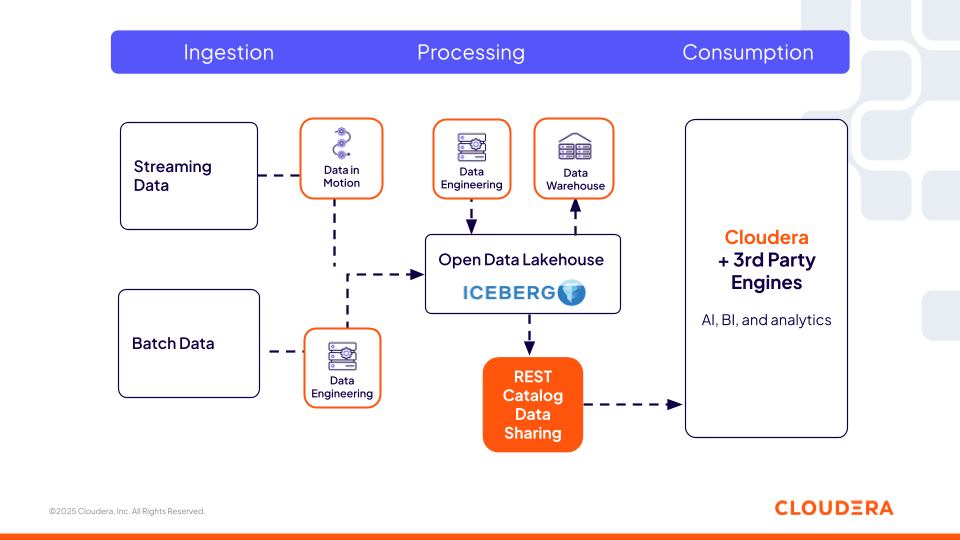
Figura 1. El catálogo REST de Iceberg de Cloudera proporciona una capa universal e interoperable de metadatos, permitiendo que herramientas de código abierto y de terceros accedan a los mismos datos.
Casos de uso reales e impacto del catálogo REST de Iceberg
Los siguientes ejemplos reales ilustran cómo las organizaciones utilizan el catálogo REST de Iceberg para simplificar su pila de datos, reducir el coste total de propiedad (TCO) y acelerar el tiempo de conversión en valor, todo ello manteniendo los datos donde deben estar.
En conjunto, estos ejemplos demuestran cómo el enfoque abierto e interoperable de Cloudera acelera los resultados de la IA, impulsa la eficiencia operativa a escala empresarial y permite la seguridad y el cumplimiento.
Intercambio de datos: escala las aplicaciones de IA a más de 3000 usuarios multiplataforma
Un fabricante de automóviles de lujo se enfrentaba a retos cada vez mayores a la hora de compartir datos de forma segura con un socio externo utilizando Databricks. Los métodos tradicionales se basaban en la duplicación de datos, lo que generaba costes, complejidad e inflexibilidad arquitectónica.
Al adoptar el catálogo REST de Iceberg, el cliente estableció un intercambio de datos seguro y sin ETL entre los sistemas internos y las plataformas externas. Este enfoque abierto y basado en estándares les permitió elegir las mejores herramientas para el trabajo, utilizando Spark para los complejos pipelines de datos e Impala para el análisis SQL rápido. Con esta base, la empresa amplió las aplicaciones de IA a más de 3000 usuarios y, al mismo tiempo, mantuvo el gobierno y el control totales del acceso a los datos.
Optimización de Data Warehouse: reduce los costes de movimiento de datos en un 74 %
Tras una actividad de fusión, una empresa global de satélites se encontró con importantes obstáculos para unificar datos fragmentados bloqueados en sistemas propietarios. Sin una capa de datos coherente e interoperable, sus iniciativas de inteligencia artificial y análisis tardaban en ampliarse y eran difíciles de gestionar.
La arquitectura abierta de lakehouse de datos de Cloudera, basada en el catálogo REST de Iceberg, ayudó al cliente a consolidar estos compartimentos y establecer una fuente única de verdad para todas sus cargas de trabajo en IA y análisis. Al consultar directamente las tablas Iceberg gestionadas en S3, eliminaron la necesidad de pipelines de datos redundantes y esfuerzos de replatforming, lo que llevó a una reducción del 74 % en los costes de movimiento de datos.
Demo: Un análisis más detallado del intercambio de datos a través del catálogo Iceberg REST de Cloudera
Esta demostración interactiva da vida al catálogo REST de Iceberg a través de un escenario de servicios financieros. En el banco ficticio Parent Bank, diferentes equipos utilizan sus herramientas preferidas, como Snowflake y AWS Athena, para acceder de forma segura a una fuente de datos regulada, todo ello sin necesidad de complejos procesos ETL ni costosos traslados de datos.
Para profundizar en esta oferta y cómo puede beneficiar a tu organización, explora estos recursos:
- Visita nuestra página de productos para obtener más información sobre el lakehouse de datos abierto de Cloudera.
- Lee el comunicado de prensa para ver el anuncio completo sobre la visión de Cloudera de compartir datos de forma abierta.