Servicio de inferencia de IA de Cloudera
Agiliza el servicio de modelos para implementar y escalar aplicaciones, agentes y asistentes de IA privados con una velocidad, seguridad y eficiencia sin igual.

Impulsa el desarrollo y la implantación de la IA a la vez que protege todas las fases de su ciclo de vida.
Gracias a los microservicios NVIDIA NIM, Cloudera AI Inference Service ofrece un rendimiento líder en el mercado, con una velocidad de inferencia hasta 36 veces superior en las GPU NVIDIA y casi 4 veces superior en las CPU, lo que agiliza la gestión y el gobierno de la IA en nubes públicas y privadas.
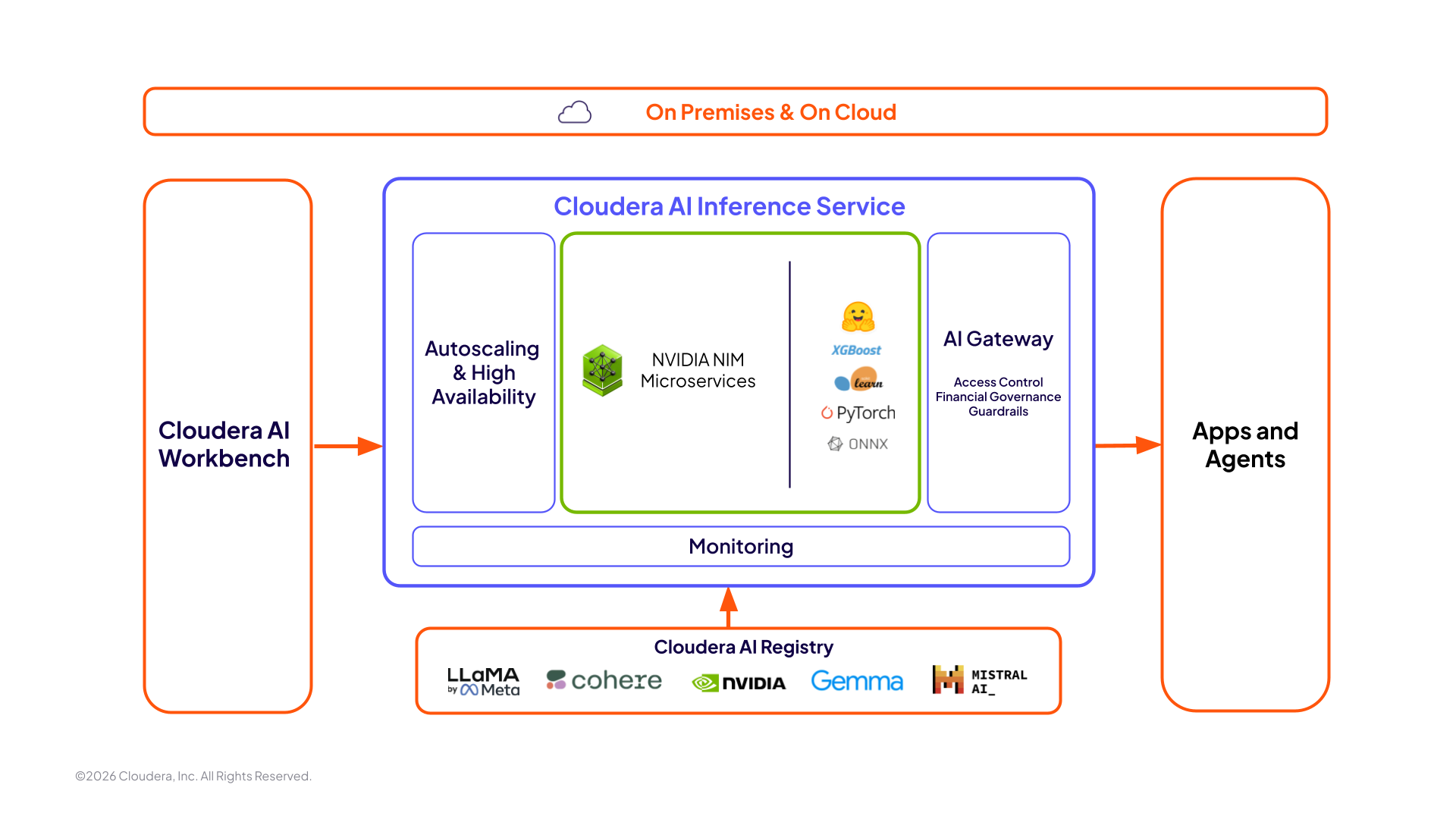
Un servicio para todas tus necesidades de inferencia de IA empresarial
Implementa con un solo clic: Traslada tu modelo de la fase de desarrollo a la de producción con rapidez, independientemente del entorno.
Un entorno seguro: Obtén una seguridad integral sólida que cubra todas las fases del ciclo de vida de tu IA.
Una plataforma: Gestiona sin problemas todos tus modelos a través de una única plataforma que se encarga de todas tus necesidades de IA.
Soporte integral: Recibe asistencia unificada de Cloudera para todas tus preguntas sobre hardware y software.
Características clave de AI Inference Service
*Característica disponible próximamente. Ponte en contacto con nosotros para obtener más información.
Opciones de implementación del servicio de inferencia de IA
Ejecuta cargas de trabajo de inferencia en el entorno local o en la nube, sin comprometer el rendimiento, la seguridad ni el control.
Cloudera en la nube
- Flexibilidad multinube: implementa en nubes públicas y evita la dependencia de ecosistemas.
- Tiempo de obtención de valor más rápido: comienza a realizar inferencias sin configurar la infraestructura; ideal para experimentos rápidos.
- Escalabilidad elástica: gestiona picos de tráfico impredecibles con autoescalado a cero y microservicios optimizados para GPU.
Cloudera en el entorno local
- Soberanía de los datos: mantén el control total. Conserva los modelos, prompts y activos completamente protegidos tras el firewall.
- Preparado para entornos desconectados: diseñado para entornos regulados como el público, la sanidad y los servicios financieros.
- TCO predecible y reducido: despídete de las sorpresas con precios fijos y TCO menor frente a las API en la nube basadas en tokens.
DEMO
Experimenta por ti mismo la implementación de modelos sin esfuerzo
Descubre lo fácil que es implementar modelos de lenguaje de gran tamaño con las potentes herramientas de Cloudera para gestionar eficazmente aplicaciones de IA a gran escala.

Integración del registro de modelos:
accede, almacena, versiona y gestiona modelos sin problemas a través del repositorio centralizado Cloudera AI Registry.
Configuración e implementación sencillas: implementa modelos en entornos en la nube, configura endpoints y ajusta el escalado automático para aumentar la eficacia.
Monitorización del rendimiento:
resuelve y optimiza a partir de métricas clave como la latencia, el rendimiento, la utilización de recursos y el estado del modelo.

Cloudera AI Inference te permite aprovechar todo el potencial de los datos a escala con la experiencia en IA de NVIDIA y salvaguardarlos con funciones de seguridad de nivel empresarial para que puedas proteger tus datos y ejecutar cargas de trabajo en el entorno local o en la nube con confianza, todo ello a la vez que implementas modelos de IA de manera eficiente con la flexibilidad y el gobierno necesarios.
Participe
Da el siguiente paso
Explora potentes capacidades y profundiza en los detalles con recursos y guías que te permitirán ponerte en marcha rápidamente.
Recorrido del producto AI Inference Service
Conoce de cerca el servicio Cloudera AI Inference.
Documentación del servicio de inferencia de IA
Encuentra todo lo que necesitas, desde descripciones de características hasta guías de implementación útiles.
Explora más productos
Acelera la toma de decisiones basada en datos desde la investigación hasta la producción con una plataforma segura, escalable y abierta para la IA empresarial
Desbloquea la IA generativa privada y los flujos de trabajo agénticos para cualquier nivel de habilidad, con la velocidad del low-code y el control total del full-code.
Aporta el poder de la IA a tu negocio de forma segura y a escala, garantizando que cada conocimiento sea trazable, explicable y confiable.
Explora el marco integral para crear, implementar y monitorizar aplicaciones de ML listas para la empresa al instante.