Cloudera Platform
Lleva la IA a los datos dondequiera que se encuentren: aprovecha todo el potencial de los datos en la nube, en los centros de datos y en el edge.

Descripción
Máxima flexibilidad en la gestión de datos, el análisis y la IA.
La plataforma de Cloudera ofrece una experiencia coherente, un gobierno unificado y un control elástico en cualquier entorno: local, nubes públicas y el edge.
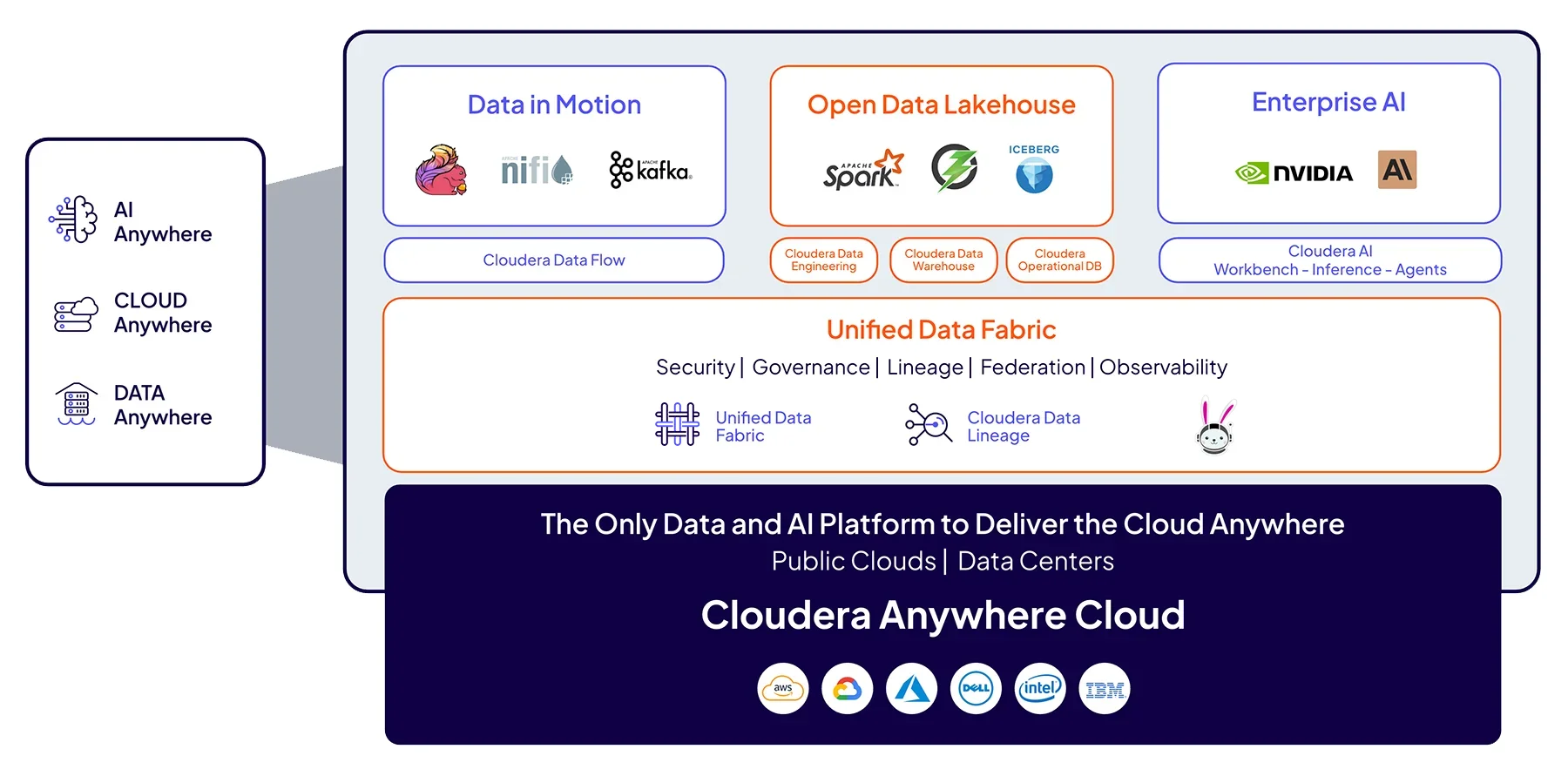
Experiencia coherente
El acceso a servicios, API e IU idénticos en todos los centros de datos y nubes permite que los equipos cambien de entorno sin necesitar nueva formación ni de cambiar de herramientas.
Elasticidad híbrida
Gestiona los picos de demanda con el escalado a la nube mientras mantienes la seguridad de los datos en el entorno local, sin necesidad de migrarlos.
Gobierno unificado
Aplica políticas coherentes de seguridad, linaje y auditoría en todos los entornos para mantener el cumplimiento normativo, independientemente de dónde se encuentren los datos.
CASOS DE USO
Potenciando casos de uso de datos e IA desde el edge hasta la nube.
Las organizaciones más grandes del mundo confían en Cloudera para obtener información estratégica que impulse sus beneficios, las proteja de amenazas y salve vidas.
-
Ofrezca una experiencia coherente en la nube
Crea una vez y ejecuta en cualquier lugar en una sola plataforma.
-
Acelere la IA empresarial
Entrena e implementa modelos de IA de forma segura en entornos locales y en la nube.
-
Crea un lakehouse de datos abierto
Consolida datos estructurados y no estructurados en un solo lakehouse abierto.
-
Análisis de flujos e IdC
Procesa y analiza datos en tiempo real desde el edge hasta la nube.
-
Ofrezca una experiencia coherente en la nube
Crea una vez y ejecuta en cualquier lugar en una sola plataforma.
-
Acelere la IA empresarial
Entrena e implementa modelos de IA de forma segura en entornos locales y en la nube.
-
Crea un lakehouse de datos abierto
Consolida datos estructurados y no estructurados en un solo lakehouse abierto.
-
Análisis de flujos e IdC
Procesa y analiza datos en tiempo real desde el edge hasta la nube.

Desarrolla, migra y ejecuta cargas de trabajo en el centro de datos y en la nube.
Una plataforma de datos sanitarios que funciona en cualquier lugar con nuestra plataforma híbrida segura, integrándose de manera fluida al entorno de cualquier cliente.

Crea, entrena y sirve cargas de trabajo de IA en cualquier lugar, con MLOps y gobierno integrados.
Un banco global aumenta la productividad de los desarrolladores un 20 % y reduce el tiempo del centro de llamadas un 10 % con nuestra plataforma de IA.

Habilita inteligencia de negocio, SQL y aprendizaje automático en tablas Apache Iceberg unificadas en entornos híbridos.
Unifica las capacidades de almacén de datos y lago de datos para admitir IA, BI y aprendizaje automático en una plataforma abierta.

Obtén información instantánea de los dispositivos del internet de las cosas (IdC) y los flujos de eventos.
Una empresa de comunicaciones global ofrece experiencias hiperpersonalizadas a millones de personas, lo que mejora la satisfacción del cliente y reduce los costes.
Características principales de Cloudera
Ejecuta aplicaciones de forma idéntica en el entorno local o en la nube sin cambios en el código. Este motor unificado permite un escalado fluido a la nube, lo que permite mover cargas de trabajo al instante para satisfacer la demanda.
Accede a servicios de datos basados en contenedores de forma integral en una única plataforma. Ingiere, diseña, almacena y ejecuta cargas de trabajo de IA y aprendizaje automático sin proliferación de herramientas, simplificando las canalizaciones y acelerando la obtención de información estratégica.
Cloudera Shared Data Experience (SDX) aplica políticas coherentes de seguridad, cumplimiento normativo y linaje de datos en entornos locales y en la nube, proporcionando un control centralizado sin sacrificar el rendimiento.
Basada en estándares abiertos como Apache Iceberg y Kubernetes, la plataforma se escala de forma elástica tanto en local como en la nube para satisfacer las crecientes demandas de datos e IA sin depender de ningún proveedor.
CLIENTES
Las grandes organizaciones confían en Cloudera para llevar la IA a los datos en cualquier lugar.
Las capacidades de nube híbrida de Cloudera ayudan a MDClone a adaptarse de manera fluida a cualquier entorno con total confianza en la seguridad de los datos. Esto significa que podemos llevar nuestra plataforma, que cambia vidas, a una amplia gama de organizaciones de investigación y proveedores sanitarios.
 Tecnología
AM BITS
Tecnología
AM BITS
 Sector público
CDC
Sector público
CDC
 Servicios financieros
Axis Bank
Servicios financieros
Axis Bank
Ecosistema de socios abierto
Nuestro amplio ecosistema de socios tecnológicos complementa nuestra plataforma abierta, lo que da la libertad de elegir las herramientas adecuadas y acelerar la innovación en cualquier lugar.
Participa
Da el siguiente paso
Para quienes ampliar sus conocimientos, nuestra completa documentación y la formación a tu propio ritmo son el siguiente paso ideal para los profesionales de los datos.
Documentación de Cloudera
Explora en profundidad detalles técnicos, guías de inicio rápido y notas de la versión de la plataforma Cloudera.
Formación gratuita
Accede a una amplia gama de cursos y rutas de aprendizaje a tu propio ritmo para perfeccionar tus habilidades.
Explora más productos
Obtén la agilidad de la nube para los datos y las aplicaciones de IA, en cualquier lugar, con potentes servicios que aceleran la innovación.
Acelera la toma de decisiones basada en datos desde la investigación hasta la producción con una plataforma segura, escalable y abierta para la IA empresarial
Recopila y transfiere tus datos desde cualquier fuente a cualquier destino de forma sencilla, segura, escalable y rentable.
Crea, orquesta y gestiona de forma segura pipelines de datos de nivel empresarial con Apache Spark en Iceberg.
Analiza grandes cantidades de datos para miles de usuarios simultáneos sin comprometer la velocidad, el coste ni la seguridad.
Gestione y comprenda el linaje de los datos y los metadatos para obtener una visibilidad completa en entornos híbridos complejos.