
Creación de aplicaciones RAG: el diablo está en los detalles
Desarrollar aplicaciones de Generación aumentada por recuperación (RAG) puede volverse complejo rápidamente, requiriendo un manejo cuidadoso de la ingesta de datos, el procesamiento y la recuperación de datos. Tradicionalmente, los desarrolladores han seguido los pasos de fragmentar datos, insertar incrustaciones e integrar bases de datos vectoriales.
Sin embargo, uno de los errores más comunes al implementar una solución RAG es no comprender cómo estos componentes son interdependientes. Los desarrolladores deben plantearse la pregunta: "¿Podemos fragmentar nuestros datos tal cual o debemos refinarlos antes de fragmentarlos?"
Data Flow de Cloudera y los procesadores exclusivos RAG Pipeline de Cloudera simplifican el complejo proceso de refinar datos no estructurados mediante la partición, permitiendo una fragmentación más eficaz y vectores de incrustación de mayor calidad. Aunque una partición o fragmentación mal diseñada puede perjudicar el rendimiento y la calidad de la incrustación, las herramientas de Cloudera abstraen gran parte de esta complejidad, agilizando el desarrollo de soluciones RAG eficientes y confiables.
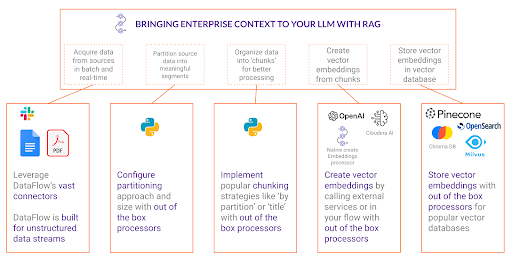
Exploremos las etapas críticas de un flujo de trabajo RAG: partición, fragmentación, incrustación e inserción, y demostremos cómo la tecnología de Cloudera simplifica cada paso.
Partición de datos: la base de RAG
El primer paso esencial en un flujo de trabajo RAG es la partición. Este proceso implica dividir fuentes de datos grandes y, a veces, datos no estructurados en segmentos significativos, lo que permite la iteración programática sobre datos no estructurados. Por supuesto, el proceso de recuperación sigue siendo posible sin particionar, pero cuanto más control granular tengas sobre el procesamiento, más flexibilidad tendrás para crear flujos para las diferentes fuentes de datos. La creación de particiones garantiza que los datos se estructuren en partes manejables que se alineen con la forma en que los usuarios consultan la información.
Las estrategias de partición varían según la naturaleza de los datos. Por ejemplo, particionar por encabezados de sección permite una recuperación más organizada al procesar documentos extensos, como los manuales de usuario. Por el contrario, particionar puede implicar desglosar el contenido por marcas de tiempo para preservar el flujo de conversación de los datos de conversación, como los registros de chat. Otra consideración clave son los límites de los tokens: dado que la mayoría de los modelos de incrustación tienen un tamaño de token predefinido que se puede procesar de una vez, las particiones deben cumplir con estas restricciones para garantizar un rendimiento óptimo.
Un enfoque de partición bien definido ayuda a mantener la precisión, la eficiencia y la facilidad de uso de las aplicaciones RAG. Los desarrolladores pueden optimizar la calidad de la respuesta asegurándose de que solo se recuperen y pasen los datos más relevantes al LLM, al mismo tiempo que minimizan la sobrecarga computacional innecesaria.
Fragmentación: garantizar la preservación del contexto
Una vez completada la creación de particiones, el siguiente paso es la fragmentación. La fragmentación consiste en agrupar particiones relacionadas para mantener un contexto significativo. Mientras que la partición divide el contenido en componentes fundamentales, la fragmentación garantiza que estos componentes conserven sus relaciones, lo que evita la pérdida de contexto.
Por ejemplo, una cláusula o regulación podría abarcar varios párrafos en documentos legales. Si las particiones son demasiado estrechas, puede perderse el sentido al recuperar contenidos a partir de una consulta del usuario. La fragmentación ayuda a agrupar segmentos de texto relacionados en una unidad lógicamente completa. Esto asegura que cuando un usuario realiza una consulta, el modelo recibe suficiente información contextual para generar una respuesta precisa y relevante.
Las estrategias de fragmentación varían según la naturaleza del conjunto de datos. Algunos enfoques implican una segmentación simple de longitud fija, donde los segmentos se agrupan según un número predefinido de tokens. Las estrategias más avanzadas pueden implicar dividir el título de un documento junto con el texto relacionado.
La fragmentación eficaz mejora la precisión de las búsquedas, optimiza la latencia de recuperación y asegura que las respuestas generadas por el LLM sean contextualmente conscientes y precisas. Además, al determinar una estrategia de fragmentación que maximice la conservación del contexto, puede guiar la decisión de tu modelo de incrustación con el conocimiento predefinido de los tamaños de los fragmentos.
Incrustación: transformar texto en vectores de búsqueda.
Con fragmentos bien estructurados, el siguiente paso en el flujo de trabajo de RAG es la integración. Las incrustaciones son representaciones numéricas de texto que permiten a las máquinas comprender y comparar el significado semántico de diferentes segmentos de texto. Sin la incrustación, las aplicaciones RAG se limitarían a búsquedas simples de palabras clave, que carecen de la comprensión contextual de una verdadera recuperación semántica.
La incrustación es un proceso de múltiples pasos que incluye la tokenización, la transformación vectorial y el almacenamiento. Cuando un fragmento de texto pasa por un modelo de incrustación, primero se descompone en tokens. A continuación, estos tokens se convierten en un vector de alta dimensión que captura la esencia del texto en un formato adecuado para búsquedas de similitud matemática, como la Distancia Euclidiana (L2) y la Similitud de Coseno.
Elegir el modelo de integración adecuado es fundamental. Algunos modelos están optimizados para la recuperación de propósito general, mientras que otros están afinados para aplicaciones específicas de dominio, como documentos legales, médicos o técnicos. Otra consideración clave es la dimensionalidad vectorial, que debe coincidir con el esquema de la base de datos vectorial. Una discrepancia en el tamaño de los vectores puede llevar a búsquedas ineficientes o problemas de compatibilidad.
Una vez que los fragmentos de texto se incrustan en representaciones vectoriales, se vuelven buscables mediante métricas de similitud. Esto permite una recuperación altamente eficiente del contenido más relevante según las consultas de los usuarios, mejorando significativamente la precisión y la capacidad de respuesta de las aplicaciones impulsadas por RAG.
Data Flow de Cloudera ofrece un procesador de incrustación increíblemente potente y fácil de usar que evoluciona las capacidades de tus flujos de datos, permitiéndote aprovechar un modelo dentro del contexto del procesador. No es necesario llamar a una API (no se requiere GPU). El procesador tiene tres propiedades simples:
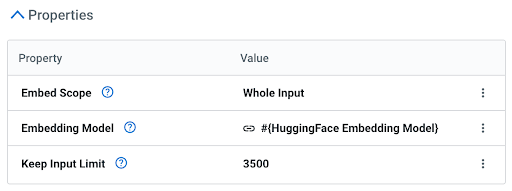
Esto te da el control detallado para elegir el mejor modelo de incrustación para cada flujo de datos.
Insertar los fragmentos incrustados en una base de datos vectorial: habilitar una recuperación eficiente
El paso final en el flujo de trabajo de RAG es insertar los fragmentos integrados en una base de datos vectorial. Las bases de datos vectoriales están diseñadas para realizar búsquedas de similitud a alta velocidad, lo que permite la recuperación eficiente de contenido relevante cuando un usuario realiza una consulta.
A diferencia de las bases de datos tradicionales que se basan en la indexación estructurada para obtener coincidencias exactas, las bases de datos vectoriales utilizan búsquedas de similitud y algoritmos como ANN y KNN para encontrar incrustaciones que coincidan estrechamente con la consulta del usuario. Esto es lo que permite a las aplicaciones RAG recuperar contenido semánticamente relevante, incluso si la redacción de la consulta difiere del texto almacenado.
Una vez que los datos incrustados se han insertado en la base de datos vectorial, el sistema está listo para realizar consultas en tiempo real. Cuando un usuario envía una solicitud, la consulta se transforma en un embedding, se compara con los vectores almacenados y se recuperan los resultados más relevantes, formando la base de la respuesta del LLM.
Data Flow de Cloudera ofrece muchos procesadores de conexión VectorDB, como Milvus, Pinecone y Chroma, con más en camino.
Agilice el desarrollo de su aplicación RAG hoy mismo
Con Data Flow de Cloudera y sus procesadores especializados de RAG Pipeline, las organizaciones ahora pueden crear, implementar y optimizar aplicaciones RAG con una facilidad sin precedentes. Al abstraer gran parte de la complejidad técnica, las soluciones de Cloudera permiten a los desarrolladores centrarse en mejorar la precisión de la recuperación, optimizar la generación de respuestas y mejorar la experiencia general del usuario.
Las empresas pueden implementar rápidamente soluciones RAG que escalen de manera eficiente y ofrezcan respuestas precisas y adaptadas al contexto al aprovechar los procesadores exclusivos de particionamiento, fragmentación, incrustación e integración de VectorDB de Cloudera.
Si quieres explorar cómo Cloudera puede ayudar a agilizar el desarrollo de tus aplicaciones RAG, ponte en contacto con nuestro equipo para una demostración o consulta nuestra documentación técnica para obtener más información.
Sigue atento a nuestra próxima inmersión en las técnicas avanzadas de optimización de la GAR.
Más información:
Para explorar las nuevas capacidades de Data Flow 2.9 de Cloudera y descubrir cómo puede transformar tus pipelines de datos, ve este vídeo.
