
Las bases abiertas de Cloudera permiten a las organizaciones acceder al 100 % de sus datos, independientemente de dónde se encuentren.
En todos los sectores, los equipos de datos se están replanteando la forma de crear y ejecutar sistemas que hagan más que almacenar información: buscan convertir los datos en inteligencia. Igual de importante es que necesitan estos sistemas para interoperar. Los modelos de IA, los pipelines de funciones, los informes de business intelligence (BI) y los trabajos por lotes suelen abarcar múltiples equipos y motores. Compartir datos más allá de esos límites sin copiarlos ni refactorizarlos es ahora un requisito de primer orden.
Tradicionalmente, las organizaciones se han basado en una arquitectura de dos niveles: almacenes de datos optimizados para la BI y la presentación de informes, y lagos de datos diseñados para la IA y el aprendizaje automático (ML) a gran escala. Esta separación tuvo un coste: movimientos complejos de datos, ingeniería especializada y almacenamiento duplicado entre sistemas que rara vez permanecían sincronizados.
La arquitectura de lakehouse abierto de Cloudera aborda este desafío, reuniendo cargas de trabajo analíticas (BI, consultas ad hoc) y de IA (IA predictiva y generativa, o IA gen) en una única base de datos gobernada. Con formatos de tablas abiertas como Apache Iceberg, esta arquitectura de datos unificada permite a las organizaciones llevar la computación a los datos (no al revés) y proporciona la base para ejecutar las cargas de trabajo de IA más cerca de los datos. Las cargas de trabajo de IA en lakehouse pueden operar directamente sobre datos regulados, versionados y de alta calidad.
Cloudera es la única empresa de plataformas de datos e IA que lleva la IA a los datos dondequiera que se encuentren. Aprovechando nuestra probada base de código abierto, ofrecemos una experiencia de nube coherente que converge las nubes públicas, los centros de datos y el borde.
La importancia de las bases abiertas para ejecutar cargas de trabajo de IA
Durante la última década, las empresas han aprendido que el rendimiento y la escalabilidad por sí solos no son suficientes, y que la flexibilidad y la interoperabilidad determinan el éxito a largo plazo. Las cargas de trabajo de IA, en particular, dependen de la capacidad de utilizar fuentes de datos, marcos y herramientas dispares sin verse limitadas por formatos o sistemas propietarios.
Ahí es donde los formatos de tabla abiertos como Apache Iceberg han remodelado la arquitectura de las plataformas de datos. Iceberg separa la definición lógica de una tabla de su disposición física de almacenamiento, lo que permite que varios motores y marcos de trabajo lean y escriban los mismos datos con plenas garantías transaccionales. Esta apertura permite evolucionar la infraestructura y adoptar nuevos motores de cómputo sin reescribir los pipelines.
La gestión de los procesos de producción requiere una plataforma unificada que pueda conectar los datos, los modelos y el gobierno en todas las etapas del ciclo de vida de la IA. En el núcleo, existen pipelines de ingeniería de datos y características que transforman continuamente datos estructurados, semiestructurados y datos no estructurados en características listas para IA, manteniendo la línea y la reproducibilidad para el entrenamiento y evaluación del modelo.
Más allá del ML tradicional, la IA generative introduce nuevos requisitos operativos. Los equipos necesitan infraestructura y acceso a los datos para la recuperación y la generación aumentada (RAG), ajustar los modelos de lenguaje de gran tamaño (LLM) de los datos privados y crear flujos de trabajo agénticos que combinen modelos, solicitudes y protocolos de contexto modelo (MCP) (API) para resolver tareas específicas de un dominio. Estas cargas de trabajo se basan en datos tabulares y no estructurados (texto, documentos, imágenes e incrustaciones), todos ellos gobernados bajo un único plano de datos y metadatos. Además, una capa de inferencia escalable es esencial para desplegar y utilizar estos modelos de forma segura y eficiente.
A medida que las cargas de trabajo de la IA se vuelven cada vez más multimodales y agénticas, el acceso a los catálogos y los metadatos pasa a ser igual de importante. Los pipelines de IA, los sistemas de recuperación y los agentes autónomos dependen de los metadatos para descubrir conjuntos de datos, reproducir estados de entrenamiento y mantener linajes. Un catálogo abierto proporciona una forma universal para que estos sistemas consulten, registren y rastreen conjuntos de datos, independientemente de dónde o cómo se procesen.
La base abierta de Cloudera permite a las organizaciones dar soporte a toda la gama de cargas de trabajo analíticas, predictivas y de IA generativa.
Plataforma unificada de datos e inteligencia artificial de Cloudera
El lakehouse de datos abierto de Cloudera unifica la ingeniería de datos, el análisis y la IA en una misma arquitectura gobernada al basarse en bases abiertas, como Apache Iceberg y REST Catalog. La plataforma está diseñada en torno al principio de que las cargas de trabajo (ya sean analíticas o de IA) deben operar donde ya residen los datos. Eliminando la fricción de mover o duplicar datos, los equipos pueden construir pipelines continuos que abarcan la incorporación de datos, transformación, análisis y operaciones de modelos, con una línea y gobierno completos.
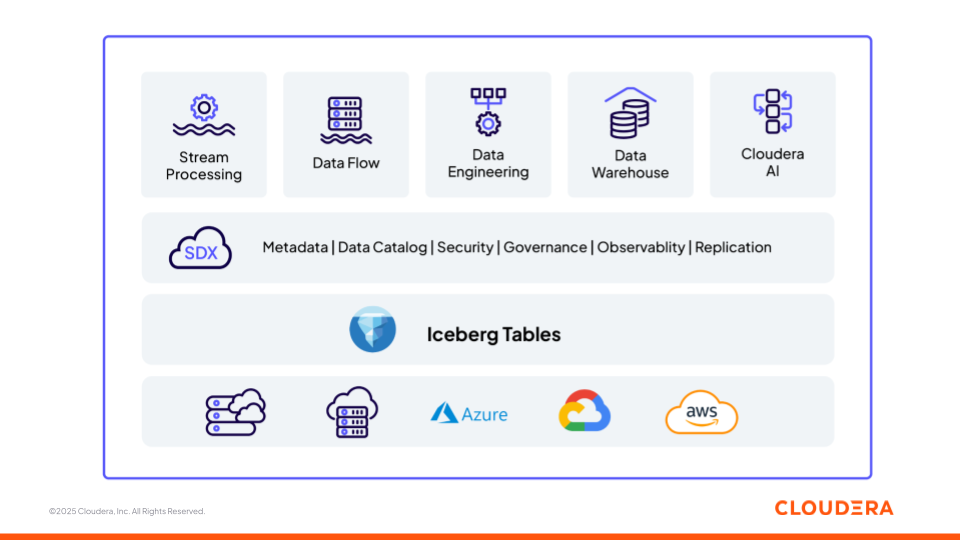
Figura 1: Plataforma de datos e inteligencia artificial de Cloudera basada en fundamentos abiertos (Apache Iceberg)
Ahora revisaremos cómo los diferentes componentes de la plataforma de Cloudera (Figura 1) apoyan a los equipos en la creación de pipelines de ML y aplicaciones de IA generativa, así como las diferentes etapas del ciclo de vida de los datos y la IA (desde la ingesta hasta la inferencia) mientras operan como una plataforma interoperable. Cada componente se basa en normas abiertas, lo que garantiza la flexibilidad y la interoperabilidad en todos los entornos.
Almacenamiento: Apache Iceberg
Apache Iceberg es el formato de tabla abierto, versionado y transaccional que sustenta la arquitectura lakehouse de Cloudera. Iceberg permite la evolución de esquemas, viajes en el tiempo y operaciones atómicas, lo que posibilita que las cargas de trabajo analíticas y de IA operen de forma coherente sobre los mismos datos gobernados. Cloudera ofrece una base gobernada y versionada que garantiza que cada modelo, prompt o tarea de recuperación se base en una visión coherente y rastreable de los datos.
Las capacidades nativas de Iceberg, como la evolución de esquemas, también se alinean estrechamente con la forma en que evolucionan los conjuntos de datos de IA. Los almacenes de funciones, los conjuntos de datos de entrenamiento y los corpus de recuperación pueden compartir las mismas tablas Iceberg en el lakehouse de Cloudera, utilizando instantáneas para congelar vistas coherentes para el entrenamiento mientras siguen llegando nuevos datos para la inferencia. Esto elimina la división entre las tablas analíticas y el almacenamiento específico de la IA.
Incorporación: Datos en movimiento de Cloudera
Cloudera DataFlow, desarrollado sobre Apache NiFi, constituye la base para el movimiento continuo de datos hacia el lakehouse. Permite la incorporación de datos de baja latencia desde diversas fuentes empresariales (bases de datos, API, dispositivos IdC y registros de eventos) para soportar tanto cargas de trabajo por lotes como de streaming. Las recientes innovaciones en la integración nativa de Apache Iceberg de NiFi ahora permiten que los datos se escriban directamente en el lakehouse abierto sin almacenamiento intermedio. Este estrecho acoplamiento entre NiFi e Iceberg reduce la complejidad del pipeline y acerca la incorporación de datos al formato de tabla abierta en sí.
En casos de uso en tiempo real, NiFi, Apache Kafka y Apache Flink forman una estructura de incorporación de datos orientada a eventos: NiFi orquesta y enruta datos, Kafka proporciona streaming duradero y Flink permite el enriquecimiento en tiempo real antes de que los datos persistan en Iceberg. Este diseño garantiza que los datos permanezcan frescos y regulados para todos los consumidores posteriores. Este flujo continuo de datos multimodales es lo que también impulsa las cargas de trabajo de IA en el lakehouse. Al hacer que los datos en tiempo real estén continuamente disponibles en las tablas de Iceberg bajo un gobierno consistente, las empresas pueden alimentar los sistemas de IA generativa con información oportuna y específica del dominio, haciendo que los pipelines RAG y los flujos de trabajo agénticos sean más precisos, fundamentados y fiables.
Catálogo: Catálogo REST de Iceberg de Cloudera
El catálogo REST de Iceberg de Cloudera (basado en la especificación REST abierta) proporciona un servicio de metadatos centralizado e interoperable que permite a cualquier motor de terceros (como Snowflake, Redshift y Databricks) que admita la especificación abierta tener acceso sin copia a las tablas Iceberg. Este es un aspecto clave para las organizaciones, ya que no se limitan a un solo motor de cálculo ofrecido por una plataforma y, por lo tanto, tienen la flexibilidad de elegir el mejor procesamiento para la tarea. Los usuarios pueden utilizar sus herramientas preferidas mientras las mismas políticas de seguridad y gobierno ofrecidas por Cloudera siguen a los datos en todas partes, garantizando la coherencia en todos los entornos.
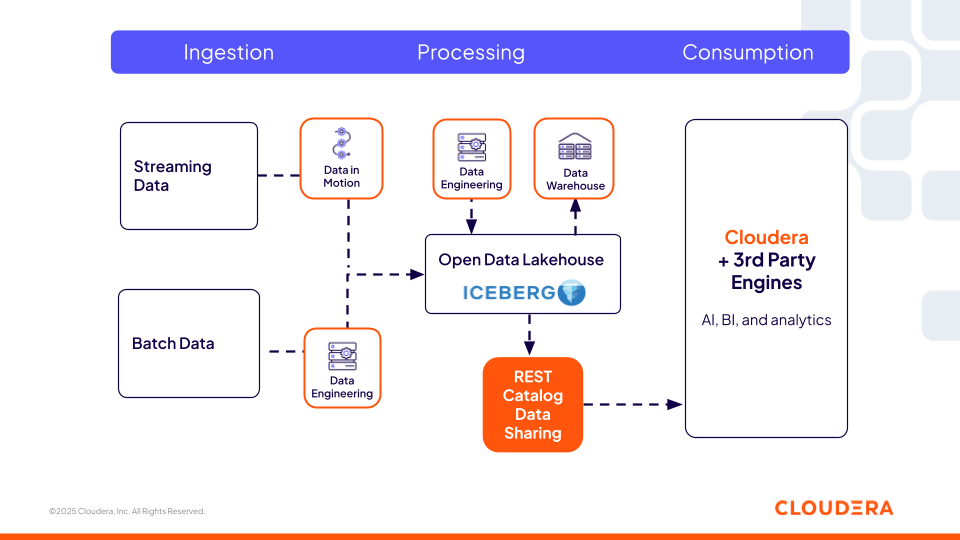
Figura 2: El catálogo REST de Iceberg de Cloudera permite la interoperabilidad con motores de terceros
Esta capa de catálogo es crítica para los pipelines de ingeniería de características, flujos de trabajo agénticos y sistemas de recuperación para localizar y acceder a conjuntos de datos gobernados de manera dinámica. Los agentes de IA pueden consultar las tablas de Iceberg mediante el catálogo REST como un gráfico de conocimiento de los datos empresariales. Pueden descubrir tablas disponibles, interpretar sus esquemas y razonar sobre metadatos de tablas, como particionamiento, instantáneas y linaje, para determinar qué conjuntos de datos utilizar.
Seguridad y gobierno: Cloudera SDX
Cloudera Shared Data Experience (SDX) es el marco unificado de seguridad y gobierno que abarca todos los servicios, desde la incorporación de datos hasta la inferencia. SDX proporciona una capa única y consistente para la línea de datos, auditoría, control de acceso y aplicación de políticas, asegurando que cada carga de trabajo herede el mismo modelo de seguridad independientemente de dónde se ejecute. Se integra con los sistemas de identidad de la empresa (LDAP, SSO, OAuth) y admite controles de acceso de granularidad fina, basados en funciones y atributos, a través de datos estructurados y no estructurados.
Al combinar SDX con la base de lakehouse abierto, Cloudera garantiza que los datos, los modelos y los agentes de IA operen dentro del mismo límite regulado, lo que proporciona transparencia, reproducibilidad y confianza tanto para las cargas de trabajo analíticas como para las de IA generativa.
Servicios de datos e IA de Cloudera
La capa de servicios unificados reúne todas las capacidades funcionales que los equipos necesitan para transformar, analizar y poner en funcionamiento la IA, mientras trabajan en los mismos datos gobernados.
Data Engineering
Cloudera Data Engineering, construido sobre Apache Spark y Apache Airflow de código abierto, ofrece un servicio serverless para construir, orquestar y escalar pipelines de datos directamente sobre tablas Iceberg, permitiendo pipelines ETL y de funcionalidades fiables y reproducibles para cargas de trabajo analíticas e IA en entornos híbridos.
Servicios de IA
La capa de servicios de IA de Cloudera operacionaliza todo el ciclo de vida de la IA, comenzando desde el entrenamiento y fine-tuning del modelo hasta el despliegue seguro, todo funcionando de forma nativa sobre la misma base de datos gobernada con Iceberg. Unifica el desarrollo de modelos, el registro y la inferencia en un único flujo de trabajo que une la ingeniería de datos y las operaciones de IA.
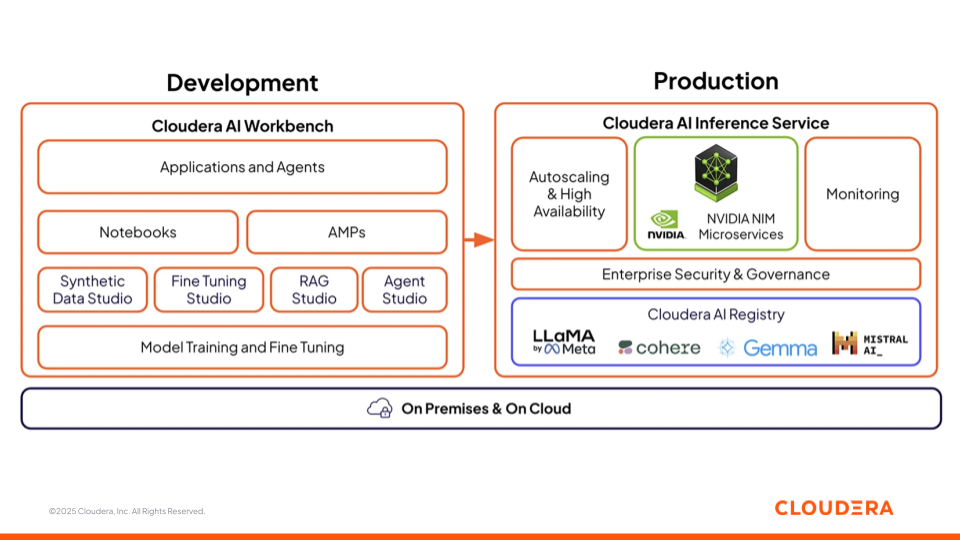
Figura 3: Oferta de Cloudera AI con AI Workbench e Inference Service
Cloudera AI Workbench
Cloudera AI Workbench es el entorno colaborativo donde científicos de datos, analistas e ingenieros desarrollan, ajustan y prueban modelos. Reúne ordenadores portátiles, creadores de aplicaciones (AMP) con poco código y estudios especializados para cada etapa del desarrollo de la IA. Para acelerar el desarrollo y despliegue de IA, Cloudera AI Workbench respalda cuatro estudios de IA que acortan la distancia entre los equipos comerciales y técnicos, fomentando la colaboración en proyectos de IA.
- Synthetic Data Studio genera conjuntos de datos sintéticos para pruebas y entrenamiento de modelos cuando los datos reales están limitados o restringidos.
- Fine-Tuning Studio adapta los modelos de base abierta con conjuntos de datos específicos de la empresa para lograr una mayor relevancia y precisión.
- RAG Studio crea pipelines de RAG que conectan los LLM (como OpenAI, Anthropic, Amazon Bedrock) con los datos privados pertinentes para obtener resultados contextuales y confiables.
- Agent Studio permite la creación de flujos de trabajo agénticos de varios pasos que utilizan modelos, MCP, API y fuentes de datos internas para automatizar tareas específicas del dominio.
Todas estas capacidades operan en el lakehouse abierto (sobre los cimientos de Iceberg), proporcionando a los equipos un acceso gobernado y sin copia a los datos necesarios para tareas específicas.
Servidores MCP de Cloudera
Cloudera también está ampliando la apertura de su plataforma de IA a través de una serie de servicios MCP emergentes, comenzando con el Cloudera AI Workbench MCP Server de código abierto. Este servicio está diseñado para la integración de sistemas de IA, lo que permite capacidades de llamada de herramientas y agentes dentro de AI Workbench. Proporciona el marco para que los LLM interactúen de forma segura con las funciones y componentes de Cloudera AI Workbench, integrando modelos, datos y aplicaciones en flujos de trabajo empresariales automatizados. En esta arquitectura, los agentes inteligentes pueden razonar, actuar y automatizar tareas en el entorno Cloudera de confianza y gobernado, manteniendo al mismo tiempo la seguridad, el control y la auditabilidad requeridas en los sectores regulados.
Cloudera AI Inference Service
El Cloudera AI Inference Service pone en producción los modelos con autoescalado, alta disponibilidad y observabilidad integral. Soporta tanto modelos de aprendizaje automático tradicionales como modelos de lenguaje de gran tamaño (LLM) y ofrece predicciones y respuestas con baja latencia. Los modelos se pueden implementar como puntos finales REST o gRPC con una seguridad de nivel empresarial, lo que garantiza un acceso fiable y coherente desde las aplicaciones y los agentes.
El Cloudera AI Registry, integrado dentro de la capa de inferencia, proporciona una gestión centralizada del ciclo de vida del modelo con APIs compatibles con MLflow para rastreo, versionado, almacenamiento de artefactos y linaje. Puedes elegir entre las distintas opciones de modelos de lenguaje abiertos y empresariales como LlaMa, Cohere, Gemma y Mistral.
La capa de inferencia también incluye supervisión y observabilidad integradas, lo que permite a los equipos realizar un seguimiento de la latencia, el rendimiento y la desviación del modelo, manteniendo al mismo tiempo un linaje completo y el cumplimiento normativo a través del gobierno de SDX. Esto garantiza que las predicciones de los modelos sean explicables y rastreables, que es un requisito clave para la IA de nivel empresarial.
El futuro está impulsado por la IA, y la IA se alimenta de todos los datos
El éxito de la IA depende tanto de la arquitectura de los datos como de la capacidad del modelo/agente. El lakehouse proporciona esa base, unificando las cargas de trabajo analíticas, operativas y de IA en un único plano de datos gobernado. Cuando se basa en estándares abiertos, garantiza que los datos, metadatos y modelos puedan interactuar entre herramientas, nubes y equipos sin fricciones.
Juntos, Cloudera AI Workbench, AI Inference Service y el AI Registry integrado completan el ciclo de vida de los datos a la IA sobre una base de lakehouse abierto. Creada directamente sobre tablas Iceberg reguladas y acceso abierto a metadatos, esta pila garantiza que todos los modelos, indicaciones y agentes funcionen con datos fiables y versionados.
El futuro de la IA empresarial no estará definido por pilas propietarias, sino por bases abiertas que unifiquen datos, gobernanza de datos e inteligencia mediante estándares compartidos e interoperabilidad transparente.
Para saber más sobre cómo preparar, integrar y analizar datos de forma segura a gran escala con Cloudera, consulta nuestras demostraciones de productos o regístrate para una prueba gratuita de 5 días.
