Desbloqueo del potencial de la IA empresarial: destilación de conocimiento para análisis de soporte al cliente





Hoy en día, las empresas se enfrentan a un gran desafío: desean aprovechar los modelos avanzados de IA para seguir siendo competitivas, pero deben controlar los altos costos de los modelos de lenguaje de gran tamaño (LLM) basados en la nube y cumplir con las regulaciones de privacidad de datos.
Entonces, ¿cómo pueden las empresas explorar la IA de vanguardia sin exceder los presupuestos o exponer datos privados sensibles? En Cloudera, hemos desarrollado una solución que convierte este desafío en una oportunidad: emplear datos sintéticos generados a partir de datos privados y la destilación de conocimientos para construir sistemas de IA rentables, precisos y conformes.
En este artículo, discutimos cómo el Synthetic Data Generation Studio de Cloudera, parte de Cloudera AI Studios, permite a las organizaciones aprovechar la innovación en IA incluso cuando los datos del mundo real son escasos o sensibles.
Caso de uso y conclusiones clave
Caso de uso: a partir de un caso de uso interno, mostraremos cómo mejoramos significativamente el rendimiento y el rendimiento general del flujo de tickets de soporte al cliente de Cloudera mediante la destilación de conocimientos utilizando datos sintéticos generados a partir de datos privados, manteniendo la privacidad de los datos y el cumplimiento normativo.
Puntos clave:
La privacidad de los datos como ventaja competitiva: los datos sintéticos permiten la innovación sin riesgo regulatorio.
Rendimiento rentable: los modelos más pequeños y afinados superan a las alternativas más grandes y que requieren muchos recursos.
Aplicable a múltiples casos de uso: el mismo enfoque puede permitir casos de uso desde la detección de fraude hasta el servicio personalizado al cliente.
Reto empresarial: equilibrar la velocidad y la precisión de los modelos de IA sin comprometer la privacidad de los datos
El equipo de atención al cliente de Cloudera aprovecha modelos de IA para analizar y resumir los tickets de soporte de los clientes en tiempo real. El sistema toma como entrada los comentarios de los clientes o de los agentes de Cloudera Support. Luego, analiza cada comentario y extrae un conjunto de análisis, como el sentimiento y la síntesis. Estos análisis son fundamentales para mejorar la experiencia del cliente en Cloudera.
Debido a la naturaleza sensible de los datos de los clientes que se procesan en este pipeline, solo se pueden usar modelos que se ejecutan en entornos locales y no se pueden compartir datos de clientes con fuentes externas.
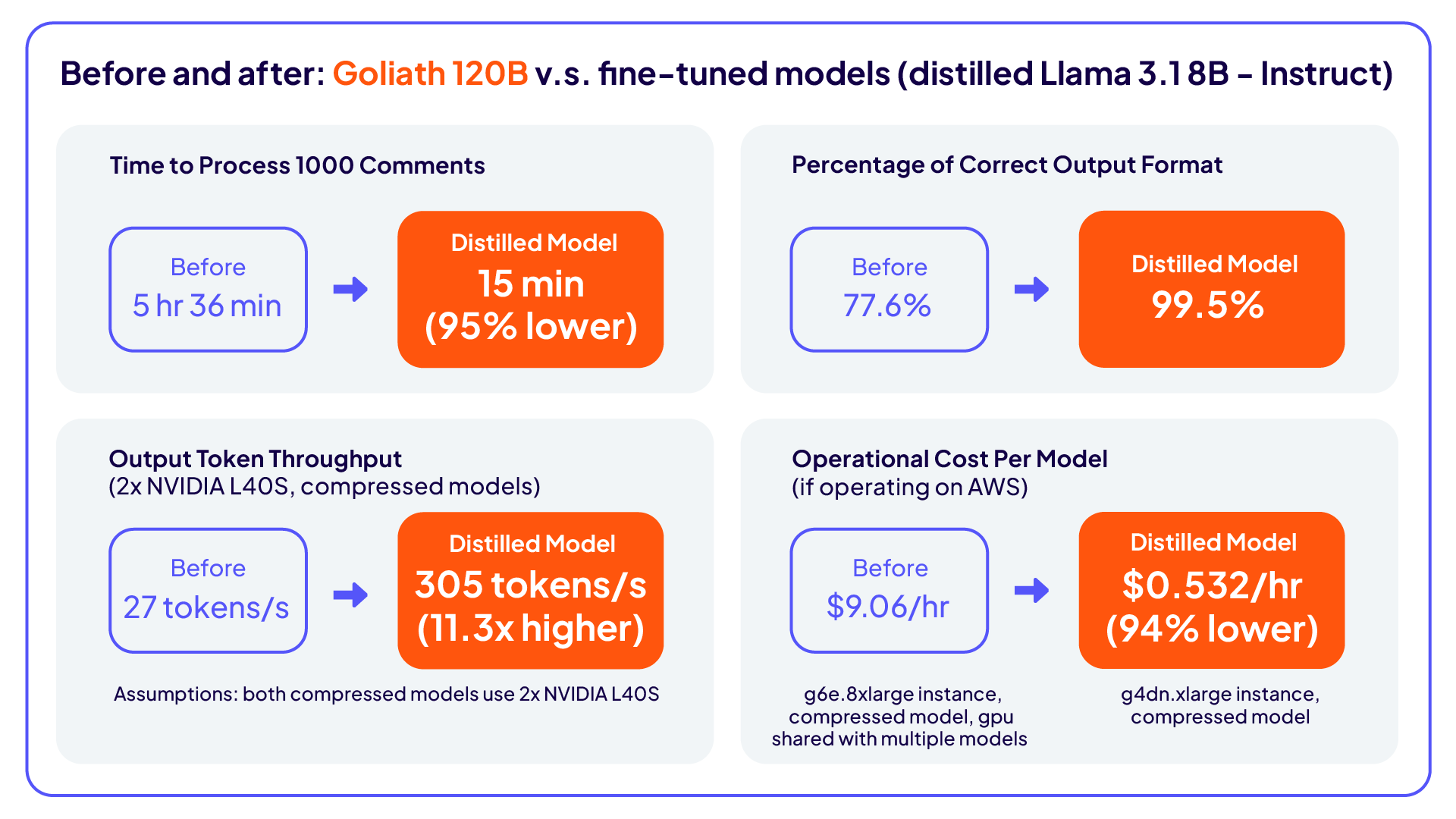
En un principio, para analizar los comentarios, el equipo se basó en LLM locales (Goliath 120B), que cumplían con los requisitos básicos de rendimiento pero eran lentos en velocidad y rendimiento de generación: de media, el procesamiento de solicitudes tomaba entre 12 y 15 segundos cada una, y las solicitudes llegaban cada 30 segundos. El cumplimiento de la producción esperado fue del 77,5 %, y la precisión de generación fue inferior a la de los modelos propietarios, lo que representa un cuello de botella para la escalabilidad y el rendimiento de los modelos de lenguaje de gran tamaño (LLM).
Los desafíos de usar grandes LLM locales (Goliath-120B) eran evidentes: tiempos de respuesta más lentos, costos más altos, menor precisión de generación que los modelos de última generación basados en la nube y riesgos de cumplimiento.
Las grandes organizaciones enfrentan compensaciones similares: equilibrar la precisión y la velocidad de la IA con los riesgos de exposición de datos.
La solución de Cloudera: destilación de conocimiento con datos privados
El avance revolucionario de Cloudera reside en un enfoque de destilación del conocimiento que pone la privacidad en primer lugar.
En lugar de entrenar modelos con datos sin procesar de clientes, que implicaban riesgos regulatorios y de exposición, generamos conjuntos de datos sintéticos utilizando Cloudera Synthetic Data Studio. Esta nueva herramienta de bajo código en Cloudera AI imitaba las interacciones del mundo real, preguntas técnicas, escenarios de solución de problemas y más, sin exponer nunca la información privada.
La generación de interacciones sintéticas de atención al cliente tuvo beneficios regulatorios y de exposición, y también permitió al equipo enviar los datos sintéticos a LLM de última generación basados en la nube para extraer información, como el sentimiento del cliente, de los LLM de mejor rendimiento. Estos LLM basados en la nube proporcionaron una extracción de información mucho más precisa que los grandes LLM locales, lo que los convirtió en una fuente ideal para destilar conocimientos precisos de estos LLM de última generación.
La solución de datos sintéticos de Cloudera eliminó cualquier riesgo de cumplimiento y privacidad y generó datos sintéticos de la más alta calidad (incluso más alta que la de las grandes LLM locales existentes). Este enfoque desbloqueó la opción de destilar conocimientos de modelos de última generación a pequeños LLM y resolver el mismo problema que el Goliath-120B, pero a un coste menor y con mayor precisión.
Nuestro proceso
Generación de datos: utilizando el flujo de trabajo de generación de datos de Synthetic Data Studio, elaboramos un mensaje que instruye a Claude Sonnet para generar preguntas y respuestas de clientes. La instrucción indica al LLM que cree preguntas y respuestas de atención al cliente, imponga el tono y detalle la estructura. Además, proporcionamos una lista de temas que aparecen en los datos del mundo real (como la atención al cliente para Cloudera AI o Cloudera Data Warehouse) y utilizamos temas iniciales para garantizar la generación de tickets de atención al cliente tanto diversos como reales.
Puesta a punto: utilizando solo los datos filtrados, el equipo dividió los datos en conjuntos de entrenamiento y desarrollo, y destiló el conocimiento del modelo Claude Sonnet a un modelo Meta Llama3.1-8B-instruct . El equipo llevó a cabo múltiples experimentos seleccionando los parámetros de ajuste fino que maximizan el rendimiento del LLM destilado.
Evaluación: utilizando el flujo de trabajo de evaluación de Synthetic Data Studio, el equipo elaboró un mensaje para instruir a un LLM como juez sobre cómo evaluar la calidad de los datos generados y eliminar las muestras de baja calidad.
Mediante evaluaciones tanto humanas como automatizadas de LLM como juez, el equipo puntuó preguntas y respuestas reales de tickets de atención al cliente. El equipo de Cloudera se centró en las respuestas, señalando que los LLM desplegados y destilados diferían, e informó sobre la tasa de éxito de cada LLM. Además, midieron las mejoras de velocidad en términos de tiempo de ejecución promedio, adherencia a la salida esperada y coste para desplegar el modelo.
Los resultados
Velocidad mejorada: el tiempo de procesamiento se redujo un 95 %.
Mejor estructura de producción: el cumplimiento de la producción aumentó del 77,5 % al 99,5 %.
Mayor precisión de los LLM: al comparar el LLM destilado más pequeño (Llama 3.1 8B) con el LLM Goliath desplegado (Goliath 120B), la tasa de éxito fue del 70 % frente al 30 % cuando se utilizó Phi-4 como juez y del 63 % frente al 37 % cuando se utilizaron evaluadores humanos para comparar los dos modelos.
Mejora del coste y la eficiencia: el modelo LLM destilado, más pequeño, redujo las necesidades de procesamiento y memoria, al tiempo que aumentó la escalabilidad en tiempo real, mantuvo la privacidad de los datos y el rendimiento mejoró 11 veces.
Los resultados son claros: las empresas pueden alcanzar la excelencia en IA sin comprometer la privacidad de los datos. Al sintetizar los datos de formación y destilar el conocimiento, las empresas evitan los compromisos entre la innovación y el cumplimiento.
Los datos sintéticos permiten la innovación sin riesgo regulatorio.
Al desarrollar un enfoque de destilación del conocimiento, Cloudera logró una reducción del 95 % en el tiempo de procesamiento, aumentó la adherencia a la estructura de salida al 99,5 % y desplegó un modelo Llama 3.1 8B destilado que superó al modelo anterior Goliath 120B en un 70–% en precisión (según Phi-4) y un 63 % en evaluaciones humanas.
Este método eliminó los riesgos de cumplimiento al evitar el uso directo de datos sensibles y también desbloqueó un rendimiento 11 veces mayor, demostrando que los modelos más pequeños y ajustados pueden superar a las alternativas más grandes y con mayor consumo de recursos tanto en velocidad como en precisión.
Prueba nuestra AMP para explorar cómo usar datos sintéticos privados para destilar conocimiento de un modelo grande a uno más pequeño en un caso de uso de soporte al cliente.