Apache Storm
Un sistema para procesar datos en transmisión en tiempo real
Apache™ Storm añade funciones de procesamiento de datos en tiempo real fiables a Enterprise Hadoop. Storm en YARN ofrece enormes prestaciones para situaciones que requieren análisis en tiempo real, aprendizaje automático y supervisión continua de las operaciones.
Storm se integra con YARN mediante Apache Slider. YARN administra Storm y también tiene en cuenta los recursos del clúster para los componentes de gobernanza de datos, seguridad y operaciones de una arquitectura de datos moderna.

Finalidad de Storm
Storm es un sistema de computación en tiempo real distribuido para el procesamiento de grandes volúmenes de datos de alta velocidad. Storm es extremadamente rápido y puede procesar más de un millón de registros por segundo y por nodo en un clúster de tamaño normal. Las empresas aprovechan esta velocidad y la combinan con otras aplicaciones de acceso a los datos en Hadoop para evitar eventos no deseados u optimizar resultados positivos.
Algunas nuevas oportunidades de negocios incluyen: gestión de servicios para el cliente en tiempo real, monetización de datos, paneles operacionales o análisis de ciberseguridad y detección de amenazas.
A continuación, presentamos algunos de los casos de uso de prevención y optimización más habituales de Storm.
| "Prevent" Use Cases | "Optimize" Use Cases | |
|---|---|---|
| Financial Services |
|
|
| Telecom |
|
|
| Retail |
|
|
| Manufacturing |
|
|
| Transportation |
|
|
| Web |
|
|
Storm es sencillo y los desarrolladores pueden escribir topologías de Storm mediante cualquier lenguaje de programación. Storm ofrece cinco características que lo hacen ideal para las cargas de trabajo de procesamiento de datos en tiempo real. Storm es:
- Rápido: en los análisis de referencia procesa un millón de mensajes de 100 bytes por segundo y por nodo.
- Escalable: con cálculos en paralelo que se ejecutan a través de un clúster de equipos.
- Tolerante a fallos: cuando un nodo de trabajo deja de funcionar, Storm lo reinicia automáticamente. Si un nodo deja de funcionar, el nodo de trabajo se reinicia en otro nodo.
- Fiable: Storm garantiza que cada unidad de datos (tupla) se procese al menos una vez o exactamente una vez. Los mensajes solo se reproducen cuando hay fallos.
- Fácil de usar: las configuraciones estándar sirven para la producción desde el primer momento. Una vez implementado, Storm se opera fácilmente.
Cómo funciona Storm
Un clúster de Storm tiene tres conjuntos de nodos:
- Nodo Nimbus (nodo maestro, similar a Hadoop JobTracker):
- Carga cálculos para la ejecución.
- Distribuye el código por el clúster.
- Inicia los nodos de trabajo en el clúster.
- Supervisa los cálculos y reasigna los nodos de trabajo en consecuencia.
- Nodo ZooKeeper: coordina el clúster Storm.
- Nodo Supervisor: se comunica con Nimbus a través de Zookeeper; inicia y detiene los nodos de trabajo siguiendo las señales de Nimbus.

Hay cinco abstracciones que ayudan a comprender el modo en que Storm procesa los datos:
- Tuplas: una lista ordenada de elementos. P. ej., una tupla de 4 puede ser (7, 1, 3, 7).
- Secuencia: una secuencia de tuplas sin enlazar.
- Spouts: fuentes de secuencias en un cálculo (p. ej., una API de Twitter).
- Bolts: secuencias de entradas de procesos y de salidas de productos. Pueden ejecutar funciones, filtrar, agregar o unir datos, así como comunicarse con las bases de datos.
- Topologías: el cálculo global, representado a nivel visual como una red de spouts y bolts (como en el siguiente diagrama).
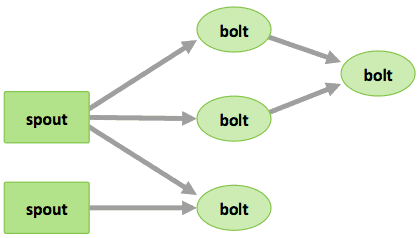
Los usuarios de Storm definen topologías para el modo de procesar los datos cuando se trata de secuencias procedentes del spout. Cuando los datos entran, se procesan y los resultados se envían a Hadoop.