Apache Tez
Un marco para aplicaciones de procesamiento de datos basadas en YARN en Hadoop
Apache™ Tez es un marco extensible para el diseño de aplicaciones de datos interactivos y lotes de alto rendimiento, coordinadas por YARN en Apache Hadoop. Tez mejora drásticamente el paradigma de MapReduce al ofrecer mayor velocidad sin renunciar a la capacidad de MapReduce para escalar a petabytes de datos. Algunos proyectos importantes del ecosistema Hadoop, como Apache Hive y Apache Pig, usan Apache Tez, al igual que un número cada vez mayor de aplicaciones de acceso a datos de terceros desarrolladas para el amplio ecosistema Hadoop.
Hive con Tez
Apache Hive, el estándar predeterminado para SQL-In-Hadoop, es ideal para consultas tanto interactivas como por lotes a escala de petabytes. Hive tiene Tez integrado, de modo que puede traducir instrucciones SQL complejas en gráficos de procesamiento de datos diseñados específicamente y altamente optimizados, que ofrecen un equilibrio entre rendimiento, capacidad y escalabilidad. Las innovaciones de Apache Tez incluyen muchas de las mejoras de rendimiento de Hive que ofrece la iniciativa Stinger, un extenso proyecto comunitario que contiene contribuciones de 145 ingenieros de 44 organizaciones diferentes. Tez ayuda a hacer que Hive sea interactivo.

Finalidad de Tez
Apache Tez ofrece un marco de trabajo y una API para que los desarrolladores escriban aplicaciones nativas de YARN que abarquen el espectro de cargas de trabajo interactivas y por lotes. Permite que esas aplicaciones de acceso a datos puedan trabajar con petabytes de datos en miles de nodos. La biblioteca de componentes de Apache Tez permite a los desarrolladores crear aplicaciones Hadoop que se integren de manera nativa con Apache Hadoop YARN y ofrezcan buenos resultados en clústeres con cargas de trabajo mixtas. Puesto que Tez es extensible e integrable, ofrece la libertad específicamente necesaria para expresar aplicaciones de procesamiento de datos altamente optimizadas. De este modo, las aplicaciones tienen ventaja sobre motores orientados al usuario final, como MapReduce y Apache Spark. Tez también ofrece una arquitectura de ejecución personalizable que permite a los usuarios expresar cálculos complejos, como gráficos de dataflow. Con ello, permiten obtener optimizaciones de rendimiento dinámico basadas en información real sobre los datos y los recursos necesarios para su procesamiento.
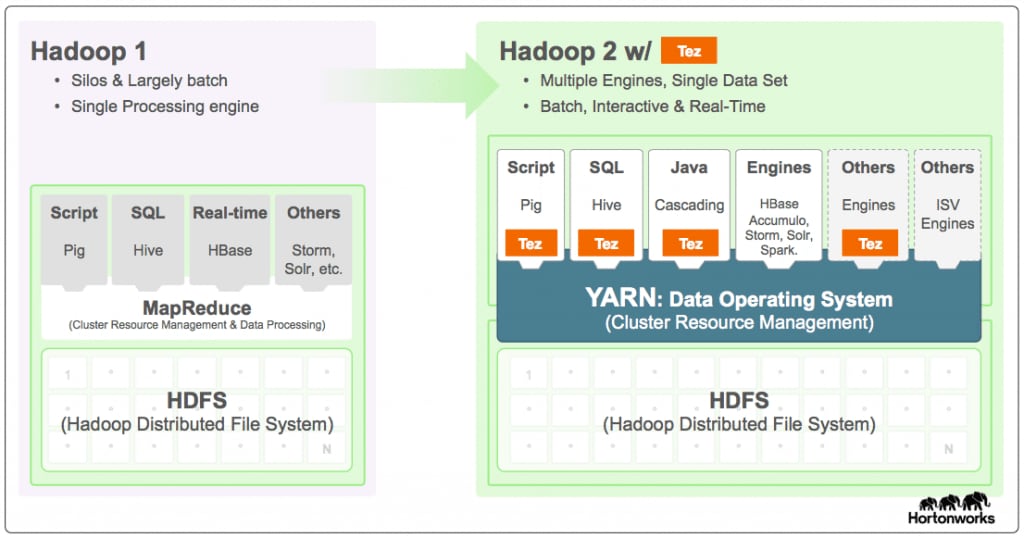
Cómo funciona Tez
Las mejoras que ofrece Apache Tez para el procesamiento de datos en Hadoop van más allá de las ventajas observadas en Apache Hive y Apache Pig. Este proyecto ha logrado un nuevo nivel de auténtica integración con YARN para las cargas de trabajo interactivas. Lea las siguientes descripciones breves para conocer cómo lleva a cabo Apache Tez las tareas esenciales.
Expresa, modela y ejecuta lógica de procesamiento
Tez modela el procesamiento de datos como un gráfico de dataflow, en el cual los vértices representan la lógica de la aplicación y los bordes muestran el movimiento de datos. Una API con gran variedad de definiciones de dataflow permite que los usuarios expresen la lógica de consultas compleja de forma intuitiva. La API se adapta bien a los planes de consultas que generan las aplicaciones declarativas de alto nivel, como Apache, Hive y Apache Pig.
Interacción de modelos entre módulos de entrada, de procesador y de salida
Tez modela la lógica de usuario que se ejecuta en cada vértice del gráfico de dataflow como composición de los módulos de entrada, procesador y salida. Los de entrada y la salida determinan el formato de los datos, además de cómo y dónde se leen o se escriben. El de procesador contiene la lógica de transformación de los datos. Tez no obliga a utilizar un formato de datos concreto. Tan solo es necesario que los formatos de entrada, procesador y salida sean compatibles entre sí.
Gráficos con reconfiguración dinámica
El procesamiento de datos distribuido es dinámico y es difícil determinar los métodos de movimiento de datos óptimos con antelación. Se proporciona más información durante el tiempo de ejecución, lo cual puede ayudar a optimizar más el plan de ejecución. Por lo tanto, Tez permite que los módulos de gestión de vértices conectables recopilen información sobre el tiempo de ejecución y que cambien el gráfico de dataflow de manera dinámica para optimizar el rendimiento y la utilización de recursos.
Rendimiento y gestión de recursos optimizados
YARN gestiona los recursos en un clúster Hadoop, que se basa en la carga y en la capacidad del clúster. El marco del motor de ejecución Tez obtiene recursos de YARN eficientemente y reutiliza todos los componentes del proceso para que no se duplique ninguna operación sin necesidad.
API para la definición de gráficos acíclicos dirigidos (DAG)
Tez define una API de Java simple para expresar un DAG del procesamiento de datos. Esta API tiene tres componentes:
- DAG: define el trabajo global. El usuario crea un objeto DAG para cada trabajo de procesamiento de datos.
- Vértice: define la lógica del usuario y los recursos y entorno necesarios para ejecutar la lógica de usuario. El usuario crea un objeto de vértice para cada paso del trabajo y lo añade al DAG.
- Edge: define la conexión entre los vértices del productor y el consumidor. El usuario crea un objeto de edge y conecta los vértices del productor y el consumidor a través de este.
Reutilización de contenedores
Tez sigue el modelo de Hadoop tradicional de dividir un trabajo en tareas individuales, todas ellas ejecutadas como procesos mediante YARN, en nombre de los usuarios. Este modelo incluye costes inherentes para el proceso de arranque e inicialización, gestionando los rezagados y asignando cada contenedor a través del gestor de recursos de YARN.