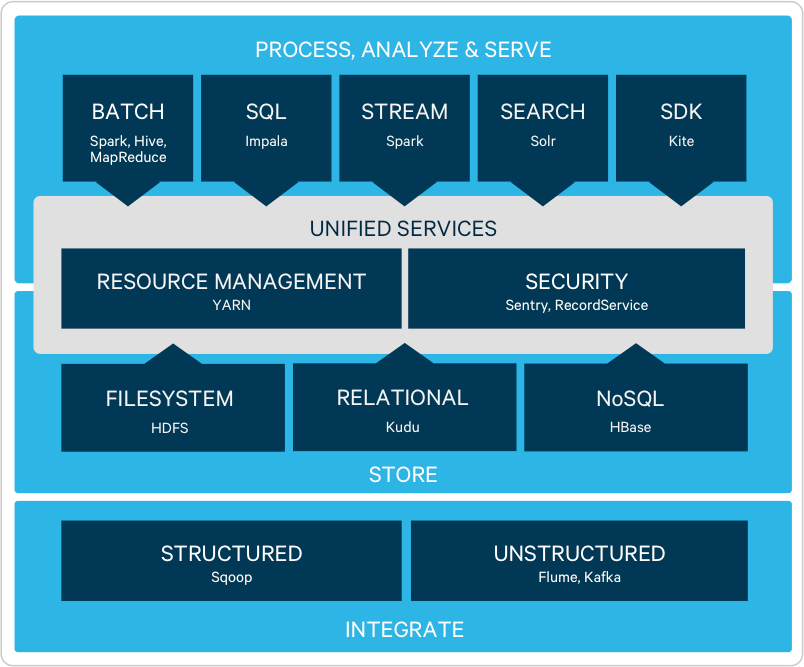
Ecosistema de Apache Hadoop
Hadoop es un ecosistema de componentes de código abierto que cambia de manera radical cómo las empresas almacenan, procesan y analizan los datos. A diferencia de los sistemas tradicionales, Hadoop permite que múltiples tipos de cargas de trabajo analíticas se lleven a cabo con los mismos datos a la vez, a gran escala, y en hardware estándar del sector. CDH —la plataforma de código abierto de Cloudera— es la distribución más popular de Hadoop y los proyectos relacionados en el mundo (se puede recibir asistencia con una suscripción a Cloudera Enterprise).
Almacena
La arquitectura de Hadoop, flexible e infinitamente escalable, se basa en el sistema de archivos HDFS y permite a las empresas almacenar y analizar cantidades ilimitadas y cualquier tipo de datos, en una única plataforma de código abierto disponible para hardware estándar del sector.


Procesa
Consigue una integración rápida con los sistemas y aplicaciones existentes para mover los datos hacia y desde Hadoop mediante el tratamiento de datos de grandes dimensiones (Apache Sqoop) o en tiempo real (Apache Flume, Apache Kafka).
Transforma datos complejos, a escala, a través de múltiples opciones de acceso a datos (Apache Hive, Apache Pig) por lotes (MR2) o mediante un rápido tratamiento de datos en memoria (Apache Spark™). Procesa datos en tiempo real a medida que llegan a tu clúster con Spark Streaming.
Explora
Los analistas interactúan con datos de la máxima fiabilidad sobre la marcha con Apache Impala, el data warehouse para Hadoop. Con Impala, los analistas se benefician del rendimiento y la funcionalidad de SQL a nivel de business intelligence, además de la compatibilidad con todas las herramientas de business intelligence más populares en el sector.
Con Cloudera Search —una integración de Hadoop y Apache Solr—, los analistas pueden acelerar el proceso de detección de patrones en datos de cualquier volumen y formato, sobre todo cuando se combinan con Impala.


Modelado
Con Hadoop, los analistas y data scientists tendrán flexibilidad a la hora de desarrollar e iterar modelos estadísticos avanzados que utilizan una combinación de tecnologías asociadas, así como herramientas de código abierto como Apache Spark™.
Proporciona los datos
El sistema de archivos distribuido para Hadoop, Apache HBase, admite lecturas/escrituras aleatorias ("datos rápidos") que requieren las aplicaciones online.

CDH: desarrollado con código y estándares abiertos
CDH —la distribución de Hadoop más popular del mundo— es la plataforma de Cloudera de código abierto al 100%. Incluye todos los componentes líderes del ecosistema de Hadoop para almacenar, procesar, explorar, modelar y proporcionar datos ilimitados. Asimismo, está diseñado para cumplir con los estándares empresariales más avanzados en cuanto a estabilidad y fiabilidad.
CDH se basa completamente en estándares abiertos para que se adecúe a las necesidades del futuro. Asimismo, Cloudera, al ser el principal promotor de estándares abiertos en Hadoop, lleva mucho tiempo aportando nuevas soluciones de código abierto a su plataforma —como Apache Spark™, Apache HBase y Apache Parquet—, que finalmente adoptó todo el ecosistema.
Descubre más información sobre sobre los componentes clave de CDH
Descubre más información sobre el código abierto y los estándares abiertos
